活用事例2:機械学習による膵がんの診断予測因子の探索的研究
次世代医療基盤法に基づき複数の医療機関から取得したデータを統合した電子カルテデータベース「DATuM IDEA®」(TOPPANホールディングス株式会社)を用いた事例を紹介します。
表題
機械学習による膵がんの診断予測因子の探索的研究:日本の電子医療記録データベースのデータを用いた後ろ向きコホート研究1Kokubo K, Iwasaki K, Matsushita I, Ito K, Asakura K. A machine learning exploration of factors affecting pancreatic cancer: a retrospective cohort study with data from the Japanese electronic medical record database. Therapeutic Research. 2023;44(5):335-345.
背景
膵がん(PC)は早期発見・早期診断が最も難しいがんのひとつと言われています。
目的
PCの早期発見・早期診断の予測因子を特定することが目的でした。
方法
PCおよびその他の消化器がんを対象とした後ろ向きコホート研究でした。
本研究では、次世代医療基盤法に基づき統合された電子カルテデータベースを使用しました。
診断や臨床検査の結果を説明変数、がんの診断(PCかその他の消化器がんか)を目的変数として、約500項目のニューラルネットワークモデルが作成されました。本モデルにより、500項目の説明変数のうち上位30項目がPCの診断に影響を与える比較的重要な変数として抽出されました。
これらの変数がPCのリスク因子であるかを評価するために、Cox比例ハザードモデル分析が実行されました。
結果
2951名の患者データが抽出されました(PC, n=465; non-PC, n=2486)。集団間の患者背景は同等でした。
Cox回帰分析により、PCの診断に有意に関連する因子として、急性扁桃炎(ハザード比[HR]= 4.51)、1型糖尿病(HR = 1.55)、女性生殖器の性状不明がん(HR = 1.52)、その他の呼吸器障害(HR = 3.63)の4つの因子が特定されました。
結論
急性扁桃炎、1型糖尿病、女性生殖器の性状不明がん、およびその他の呼吸器障害の4要因がPCの診断に関連している可能性が示されました。ただし、臨床応用可能性は、今後の研究で検証される必要があります。
活用事例2の特徴・制約
この研究事例では、電子カルテデータの医師による確定診断の情報、および臨床検査での異常有無の情報が用いられました。これらは、レセプトデータで得られるレセプト病名の可能性がある曖昧な診断情報とは異なり、情報としての正確性が高いと考えられます。また、レセプトデータでは捕捉できない検査結果の情報も利用されました。
一方で、研究当時のデータベースには以下のような制約がありました。
データベースに反映されていない、テキストベースの臨床所見、画像診断結果、および外科的治療のデータは考慮されておらず、説明変数が限られていました。将来的には、これらの項目に関する情報を含むようにデータベースが拡張されることで、モデルの精度が向上する可能性があります。
研究実施当時のデータは18か月分に限られており、選択基準を満たす患者数は小規模にとどまりました。将来的には、長期間のデータが利用できるようになり、より大規模な機械学習モデルを構築できる可能性があります。
総括
以上、RWDを用いた研究事例を2つ紹介しました。レセプトデータと電子カルテデータでは得られる情報の種類や質に一長一短が存在しますが、今後、次世代医療基盤法に基づき電子カルテデータとレセプトデータの患者単位でのシングルソース化が予定されています。そのようなデータベースを用いることで、1つのデータソースから経済性と有効性・安全性を一気通貫で考慮した費用対効果の評価が可能になるなど、RWDの活用可能性は広がりが見込まれます。
ファーマベースについて
本コンテンツ「ファーマベース」はTOPPANが運営するメディカル・ナレッジ・ベースです。
製薬企業メディカルアフェアーズの主要業務を深掘りし、網羅的・体系的に情報を発信しています。
日々の業務にご活用ください。
医療情報分析・提供サービスDATuM IDEA® について
DATuM IDEA® は、認定医療情報等取扱受託事業者との連携により収集された医療現場由来のリアルワールドデータをご提供する、TOPPANの医療情報分析・提供サービスです。
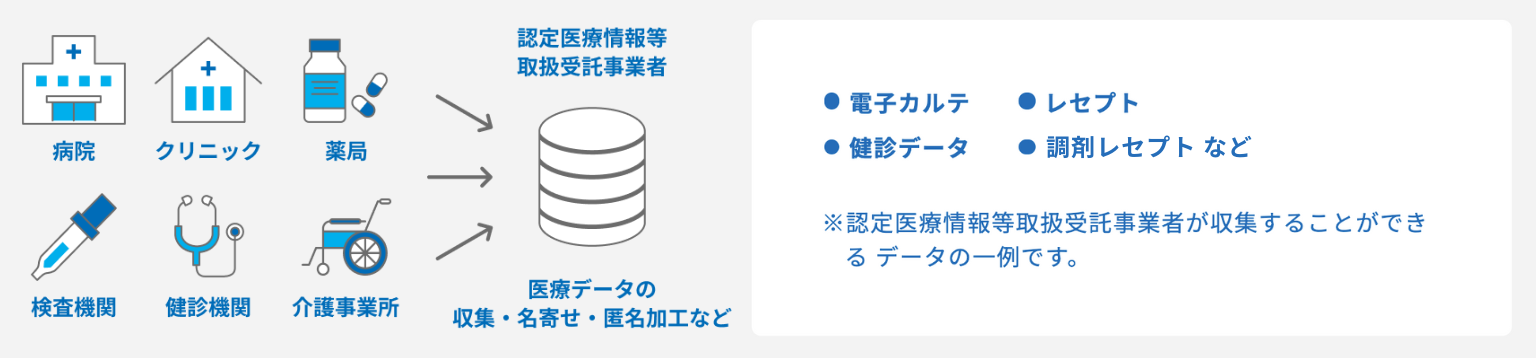
製薬企業やアカデミア、医療機関などお客様のニーズに応じてご利用いただけるよう、「Webツール(ダッシュボード)」「解析・レポート」「データセット提供」などのサービスをご用意しています。
サービス資料もダウンロードいただけますので、ぜひご活用ください。
関連情報
- 1Kokubo K, Iwasaki K, Matsushita I, Ito K, Asakura K. A machine learning exploration of factors affecting pancreatic cancer: a retrospective cohort study with data from the Japanese electronic medical record database. Therapeutic Research. 2023;44(5):335-345.